Of mermaids and machines
Don’t freak out. It’s just a yard. (Photo: Wikimedia Commons)
In historical research, computers compensate for some of the limitations of the human brain — but historical sources often pile new complexities onto the existing challenges of machine learning; for example, how to accurately “read” text on decayed documents or interpret information that hasn’t been documented in a standardized way. The humans involved also present challenges for mining historical data. We as historians (as well as every rando on the internet!) have access to mountains of data, but many of us haven’t been trained in manipulating databases of the size and complexity we’re using. It can be challenging to find what we need in the proverbial haystack — and to interpret it correctly.
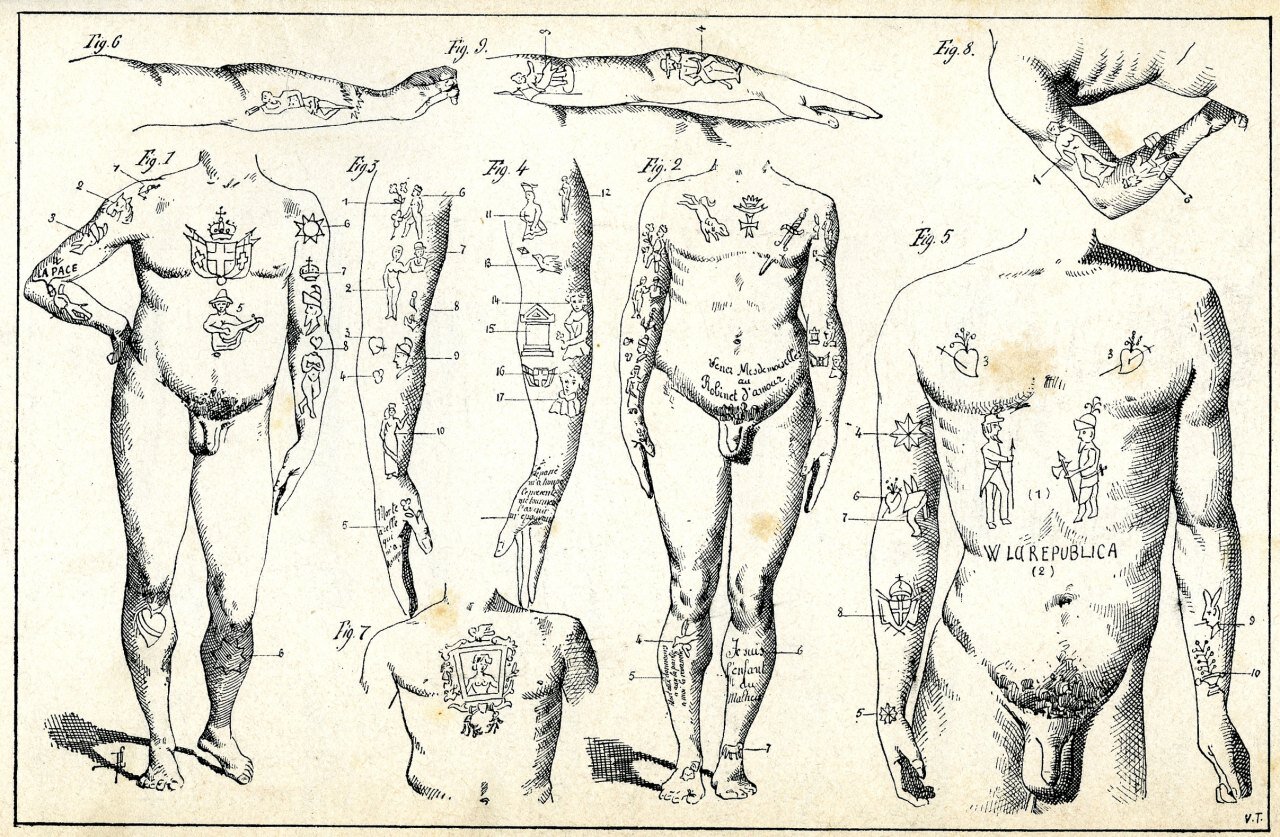
Whether a database begins with manual entry like the Digital Panopticon or machine reading like Google’s DeepMind, old stuff is hard for computers to work with. Historians at the Digital Panopticon project had to identify patterns in language and note-taking in British penal records to create searchable descriptions for 19th-Century convicts’ tattoos. The information was already digitized, but the fields with tattoo details contained other physical descriptors as well, and the notes certainly weren’t written with computers in mind. In a description reading “tattoo on the left and right arm,” the body part only appears once, but the modifier appears twice. Before the site’s search engine could produce a list of, say, female convicts with tattoos on their left arms, it had to learn that a body part at the end of the sentence can apply to multiple modifiers that come before it. Similarly, in archeological AI projects in which a computer “reads” a historical artifact, humans must define for the computer how to reconstruct and reorder documents scrambled by fissures, fading, breaks, and other marks of decay. “The tasks in archaeology are classical computer vision problems,” says [Ayellet Tal, an archaeological and computer science researcher at Israel’s Technion University]. “But they are much more difficult in archaeology because the objects are not nicely behaved.” A DeepMind project called Pythia, created to fill in the blanks in fragmented ancient Greek inscriptions, has broken new ground in archeological computing by using what it’s learned to make algorithmically-informed decisions.
The outcome of all this data-crunching is very humanizing, not least because it helps uncover stories that didn’t make the history books. The scattered records from Britain and its penal colonies revealed intimate pieces of everyday people’s stories: their values, who they loved, how they lived, and what they found beautiful. That’s pretty powerful in itself, but I was intrigued by an even less common story. Most women tattooed the names of their lovers or other relationships on their bodies. But I found myself following the rabbit trail of one of the outliers: A tiny, 20-year-old petty thief named Ann Gough with an anchor, a mermaid, a heart, and a sun tattooed on her arm. This much more closely matches descriptions for mens’ tattoos, and I found that she was quite a rebel: She absconded twice within the first year of her transportation to Australia. I wanted to get to know her — and it turns out there’s enough information in the database to piece together quite a few details of her life.

An image of Ann Gough’s conduct record. Source: Libraries Tasmania.
Not only can text analysis reveal new clues about untold histories, it can help connect dots. Using JSTOR and the HathiTrust digital library, a team of researchers has begun to find new connections between activist movements by Black women: “One aspect of the research involved exploration of the post-World War I Black Women’s Club and the New Negro movement. A keyword search revealed that many of the documents that referenced one topic also referenced the other, confirming Mendenhall’s prediction that these historical activities were linked,” says a report by the National Science Foundation. Using these terrifying avalanches treasure troves of data, we can come to new understandings about political history and social movements.
With the proliferation of data-mining resources, the bar is higher than ever for historians to understand the context of the data we’re searching and analyzing. In their TEDx Talk, researchers Erez Lieberman Aiden and Jean-Baptiste Michel demonstrate how easy it is to misinterpret Google NGram data, which provides language statistics from millions of published books: A search of the word “best” would lead one to believe it originated around 1800. However, the word was used just as frequently before that time — just spelled with a curly “f.”

A still from Aiden and Michel’s TEDx Talk, “What we learned from 5 million books.”
Mistakes are that easy, as is the potential to bend data to confirm our existing predictions or biases. There’s still a lot of room for human innovation in the field of historical data mining — both in teaching computers how to accurately “read” historical artifacts and in becoming more skilled at interpreting massive quantities of data. But more important than moving forward, our discipline must adapt to equip historians to use existing resources well.